CVPR 2025|Tripo AI and Beihang University Open-Source MIDI: Generating Compositional 3D Scenes from a Single Image

This work is led by researchers from VAST, Beihang University, Tsinghua University, and the University of Hong Kong. The first author is Zehuan Huang, a Master's student at Beihang University, whose research focuses on generative AI and 3D vision. The corresponding authors are Yanpei Cao, Chief Scientist at VAST, and Lv Sheng, Associate Professor at Beihang University.
With Sora igniting a revolution in world models, 3D scenes, as the digital bedrock of the physical world, are becoming critical infrastructure for building dynamic and interactive AI systems. Current breakthroughs in generating 3D assets from single images have provided the atomic capability of "from imagination to 3D" for 3D content creation.
However, as technology evolves towards composite scene generation, the limitations of single-object generation paradigms become apparent. Existing methods generate 3D assets like scattered "digital atoms," struggling to self-organize into "molecular structures" with reasonable spatial relationships. This leads to several core challenges: ① Instance separation dilemma (how to accurately decouple overlapping objects from a single view); ② Physical constraint modeling (how to avoid unrealistic intersections and collisions); ③ Scene-level semantic understanding (how to maintain consistency between object function and spatial layout). These bottlenecks severely hinder the efficient construction of "interactive worlds" from "digital atoms."
Recently, a research team from Beihang University, VAST, and other institutions introduced a novel model – MIDI – which can generate high-geometric-quality, instance-separable 3D composite scenes from single images, achieving a breakthrough in single-view 3D scene generation and laying the foundation for generating interactive worlds.

- Paper: https://arxiv.org/abs/2412.03558
- Project Page: https://huanngzh.github.io/MIDI-Page/
- Code: https://github.com/VAST-AI-Research/MIDI-3D
- Online Demo: https://huggingface.co/spaces/VAST-AI/MIDI-3D
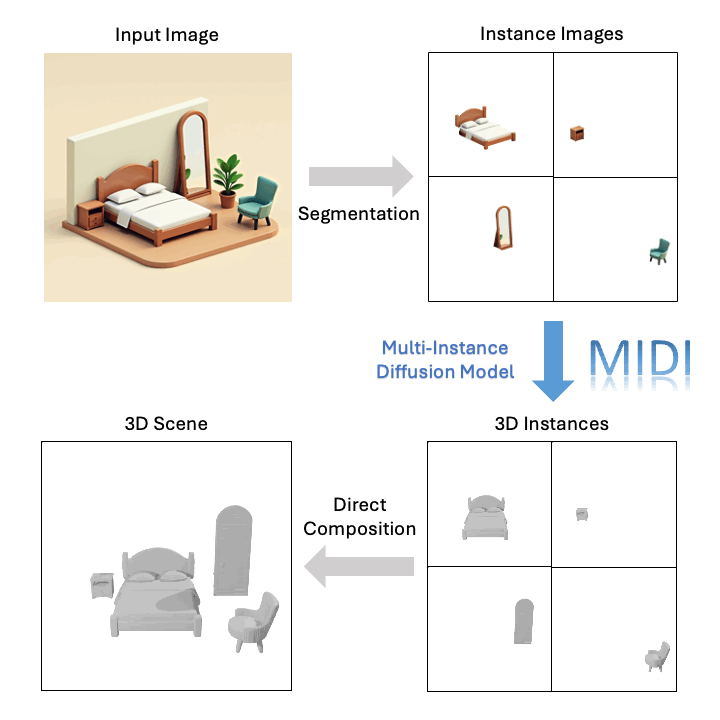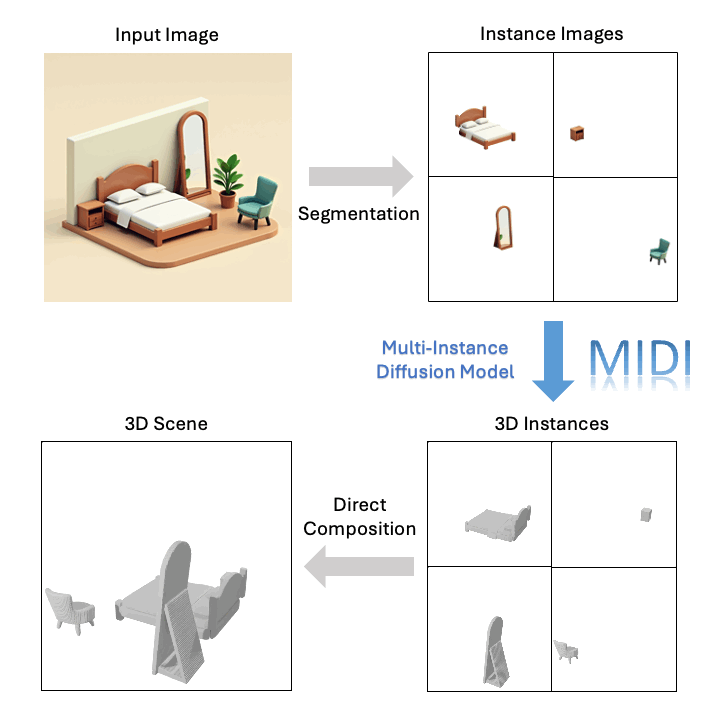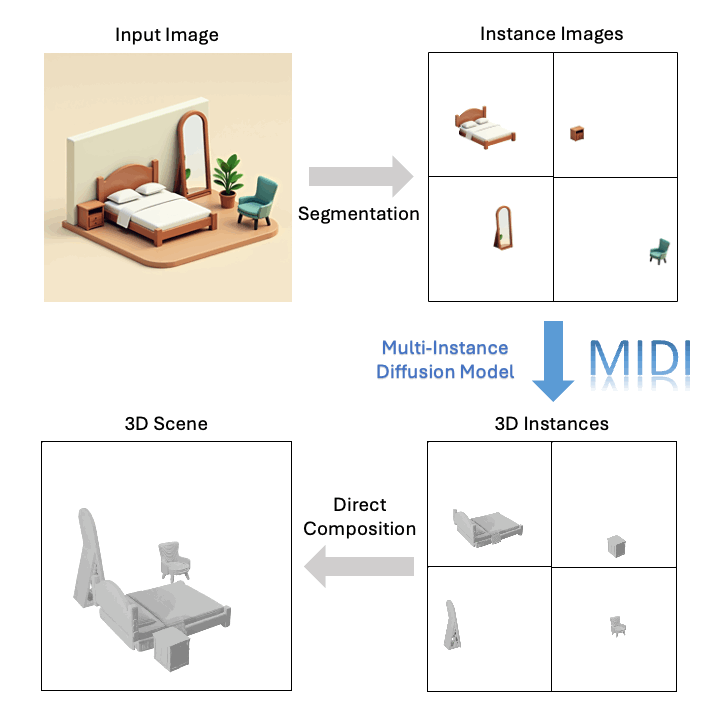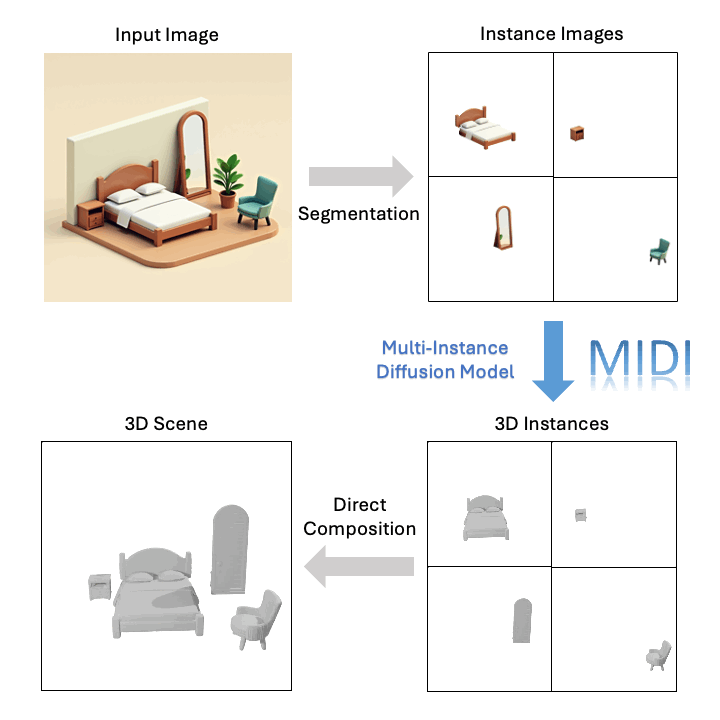
Technological Breakthrough
Traditional compositional 3D scene reconstruction techniques often rely on multi-stage, object-by-object generation and scene optimization, resulting in lengthy processes and often generating scenes with low geometric quality and inaccurate spatial layouts. To address these issues, MIDI (Multi-Instance Diffusion Model) innovatively leverages 3D object generation models, extending them into a multi-instance diffusion model capable of simultaneously generating multiple 3D instances with precise spatial relationships, achieving efficient and high-quality 3D scene generation:
- From Single Object to Multi-Instance Generation: By simultaneously denoising the latent representations of multiple 3D instances and introducing interactions between multi-instance tokens during the denoising process, MIDI extends 3D object generation models to simultaneously generate multiple instances with interaction modeling, which are then directly combined into a 3D scene.
- Multi-Instance Self-Attention Mechanism: By extending the self-attention mechanism of object generation models to multi-instance self-attention, MIDI effectively captures spatial correlations between instances and the coherence of the overall scene during the generation process, eliminating the need for per-scene optimization.
- Data Augmentation during Training: By supervising the interaction between 3D instances using limited scene data while augmenting the training with object data, MIDI effectively models scene layouts while maintaining the generalization capabilities of pre-training.
Generated Results
Based on a single image, MIDI can generate high-quality compositional 3D scenes:




Online Demo
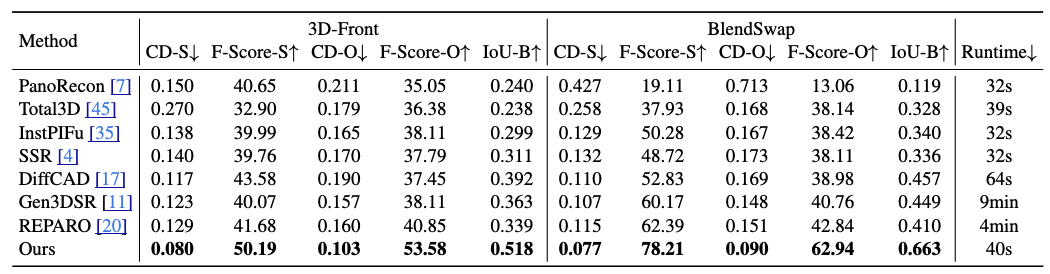
Superior Performance
MIDI is characterized by its precise spatial layout modeling, superior geometric generation quality, generation efficiency, and broad applicability. Experimental results demonstrate that the model outperforms existing methods on multiple datasets, achieving excellent performance in 3D instance spatial relationships, 3D instance geometric quality, and end-to-end generation speed.
Applications: A New Tool for 3D Scene Content Creation
MIDI provides a novel solution for 3D scene creation. This technology shows great potential in various fields such as architectural design, virtual reality, film special effects, and game development. With its high-accuracy, high-geometric-quality 3D scene generation capabilities, MIDI can meet the demand for high-quality content in complex scenes, offering creators more possibilities.
Tripo: AI-Powered 3D Model Generator
As MIDI revolutionizes 3D scene composition, Tripo enhances individual asset creation with cutting-edge AI capabilities:
Single Image to 3D Model
- Convert a single 2D image into a high-quality 3D model instantly.
- AI-powered reconstruction ensures accurate shape and texture.
- Ideal for quick prototyping and concept visualization.

Multi-Image to 3D Model
- Use multiple images from different angles for better depth and detail.
- Enhances geometric accuracy and realism.
- Perfect for precise object modeling and product design.

Text to 3D Model
- Generate 3D models from simple text descriptions.
- AI interprets prompts to create detailed, creative assets.
- Speeds up concept generation for games, VR, and animation.

Auto Rigging & Animation
- Instantly rigs models for animation with minimal effort.
- AI-driven bone structure and motion generation.
- Makes models game-ready for seamless integration.

Future Work
Despite the model's excellent performance, the MIDI development team recognizes that there are still many areas for improvement and exploration. For example, further optimizing the adaptability to complex interactive scenes and improving the detail of object generation are key focuses for future efforts. The team hopes that through continuous improvement and refinement, this research direction will not only drive the advancement of single-view composite 3D scene generation technology but also contribute to the widespread adoption of 3D technology in practical applications.